10-mn tuto : Installer un LLM local sur Windows avec Ollama

Dans le post précédent, j’ai proposé des angles d’approche pour permettre au plus grand nombre d’appréhender les dernières innovations en termes d’IA. Maintenant, il est somme toute logique que je donne le bon exemple sous l’angle de la vulgarisation techno 🙂
Comme le suggère le titre du post, je vous propose un tutoriel rapide, simple et efficace pour installer votre propre instance de grand modèle de langage, ou LLM, localement sur un PC sous Windows en utilisant Ollama.
Avant-propos: Cet article, augmenté d’améliorations générées avec des IA (Napkin , Google AI, Perplexity), est mis à disposition au travers de la license CC BY-ND 4.0![]()
![]()
![]()
C’est quoi un LLM ?
Très bonne question, merci de l’avoir posée 😀 Un LLM (Large Language Model) est un modèle d’intelligence artificielle entraîné sur d’énormes quantités de données textuelles pour comprendre et générer du langage humain, apprenant ainsi à prédire les mots suivants dans une séquence.
Parmi les modèles les plus connus du grand public :
- Disponibles au travers de ChatGPT, les modèles GPT de OpenAI (GPT-4o, o3 et o4-mini).
- Grok, par xAI, qui est pleinement intégré à X.
- Google Gemini, mis en avant au travers des outils Google tels que Gmail,Google Drive, Google Docs, etc…
- Les modèles LLama de Meta, qui sont pleinement intégrés à Facebook, Instagram et WhatsApp, sont rendus Open Source depuis la sortie de LLama 2 en juillet 2023 (Dépôt GitHub).
À partir de cette capacité fondamentale, les applications de ces modèles IA sont nombreuses :

- Chatbots avancés
- support client automatisé,
- FAQ interactive.
- Traitement de données à grand volume
- Résumés,
- Extraction, raffinage puis classification.
- Traduction automatique
- Pour mon article précédent, j’étais bien content d’avoir accès à des LLM pour traduire des articles universitaires chinois !
- Génération de code informatique,
- Beaucoup utilisé pour l’aide au codage, j’utilise GitHub Copilot pour harmoniser le code Markdown de ce blog !
- Simulation de raisonnement
- Les dernières évolutions dans ce domaine sont vraiment intéressantes. Outre le modèle DeepSeek-R1, j’expérimente beaucoup avec l’option de Recherche Profonde de Gemini Pro 2.5.
10 minutes chrono pour installer un LLM sur un PC Windows, c’est possible !
Vraiment ?
OK, c’est sûr que vous n’allez pas faire tourner des inférences avec des centaines de milliards de paramètres sur votre laptop, et encore moins des modèles commerciaux, mais pas de souci pour faire tourner des LLM plus modestes mais suffisamment performants pour s’amuser !
C’est quoi l’intérêt d’un LLM local ?
Personnellement, je n’y vois que des avantages

- Accès à une multitude de LLM Open Source récents, y compris des modèles de raisonnement comme DeepSeek-R1 ou Qwen 3.
- Confidentialité garantie : une fois le modèle sur le PC, aucune donnée ne quitte l’ordinateur, protégeant ainsi les données échangées avec le modèle (textes, images).
- Pas d’abonnement pour les fonctionnalités disponibles.
- Possibilité de redonner un second souffle à des PC un peu moins récents. Pour exemple, j’ai reconditionné un vieux laptop avec un Core-I5 et 16 GB de RAM en serveur perso avec une distri Ubuntu, et je fais tourner un petit modèle dessus !
C’est quoi les composants ?
Ollama
Disponible sur Linux, MacOs, WIndows et Docker, cette plateforme logicielle Open Source permet la gestion et l’exécution locale de modèles de langage.
- Site web : https://ollama.com
- Discord : https://discord.com/invite/ollama
- Liste des modèles disponibles : https://ollama.com/library
- Il est possible de s’inscrire ici pour publier et partager ses propres modèles.
- Dépot GitHub : https://github.com/ollama/ollama
Hollama - Client Webchat pour Ollama
Disponible également sur Linux, MacOs, WIndows et Docker, cette application est un client Webchat compatible Ollama et OpenAI.
- Dépot GitHub : https://github.com/fmaclen/hollama
- Live demo : https://hollama.fernando.is/
J’ai choisi Hollama pour sa simplicité d’utilisation, notamment pour charger de nouveaux modèles directement au travers de l’interface graphique.
Prérequis système
Pas besoin d’une carte graphique dédiée ou d’un PC Copilot +, la config suivante vous permet de faire vos premières armes !
| Composant | Configuration minimale |
|---|---|
| Système d’exploitation | Microsoft Windows 10 ou Windows 11, édition Famille ou Professionnel, maintenu à jour avec les derniers correctifs |
| CPU | 4 coeurs, Intel/AMD, x86-64 |
| RAM | 8GB |
| Stockage | 10GB disponibles |
| Connectivité Internet | Requise pour l’installation des composants et le téléchargement des modèles de langage. |
J’ai validé ce tutoriel sur des machines virtuelles qui utilisent cette configuration minimale, vous pouvez y aller les yeux fermés 😉
Modèle de langage utilisé dans le tutoriel - gemma3:1b-it-qat
gemma3:1b-it-qat désigne un version légère et efficace du modèle Open Source Gemma 3 de Google:
- 1 milliard de paramètres (“1b”).
- Instruction-tuned ("it") : Optimisé pour suivre des instructions et répondre de manière conversationnelle, ce modèle est idéal pour la génération de texte, le résumé et la traduction.
- Quantization-Aware Trained ("qat") : Entraîné pour supporter la quantification (par exemple en 4 bits), ce qui réduit considérablement la mémoire nécessaire tout en maintenant une qualité proche des modèles plus lourds.
C’est comment qu’on fait ? (Guide étape par étape)
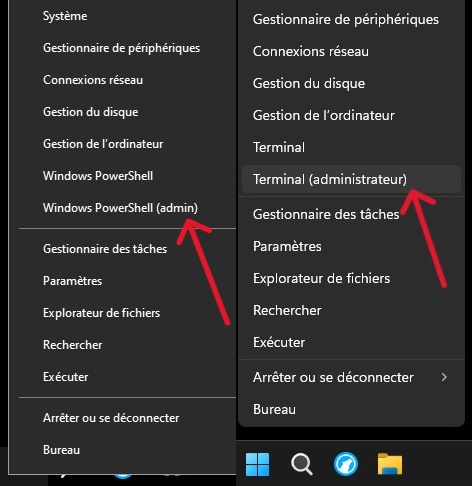
Ouvrez PowerShell en mode administrateur
-
Clic-droit sur le menu Démarrer et sélectionnez « Terminal (Administrateur) » ou «Windows PowerShell (Admin) ».
-
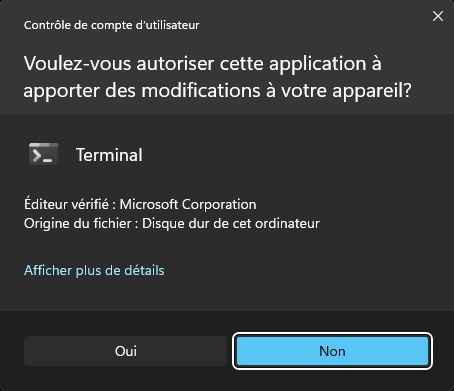
Cliquez sur [Oui] pour accepter l’élévation de privilèges.
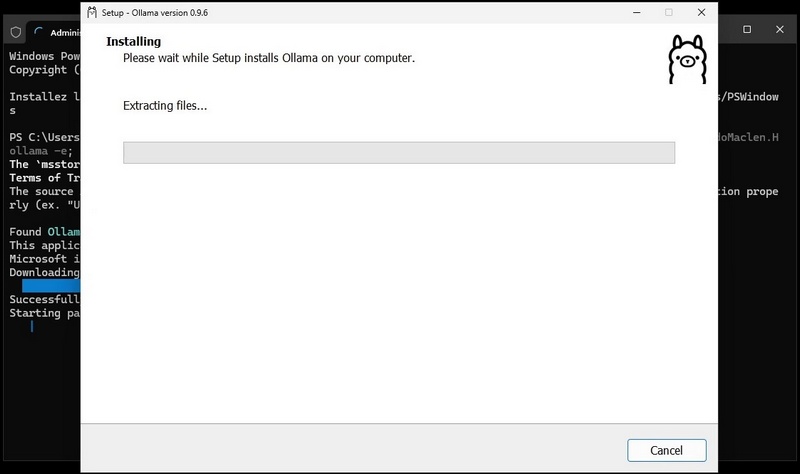
Installez un instance locale Ollama, installez l’interface graphique et récupérez le modèle gemma3:1b-it-qat en une seule ligne de commande
- Exécutez cette commande :
winget install --id=Ollama.Ollama --accept-source-agreements -e; winget install --id=FernandoMaclen.Hollama -e; ollama pull gemma3:1b-it-qat; shutdown -r -t 0- Une fois le paquet téléchargé et vérifié, le processus d’installation de l’instance Ollama commence, et l’interface graphique d’installation Ollama s’affiche.
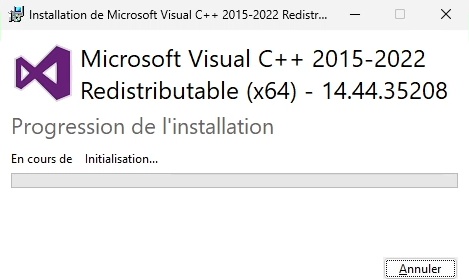
- Durant l’une dernières étapes de ce premier processus d’installation, l’installation du Redistribuable Microsoft C++ 2015/2022 peut s’effectuer de manière automatique s’il n’est pas présent sur le système.
- À la fin du processus d’installation de l’instance Ollama, une fenêtre de bienvenue s’affiche. Vous pouvez cliquer sur [Finish] pour la fermer.
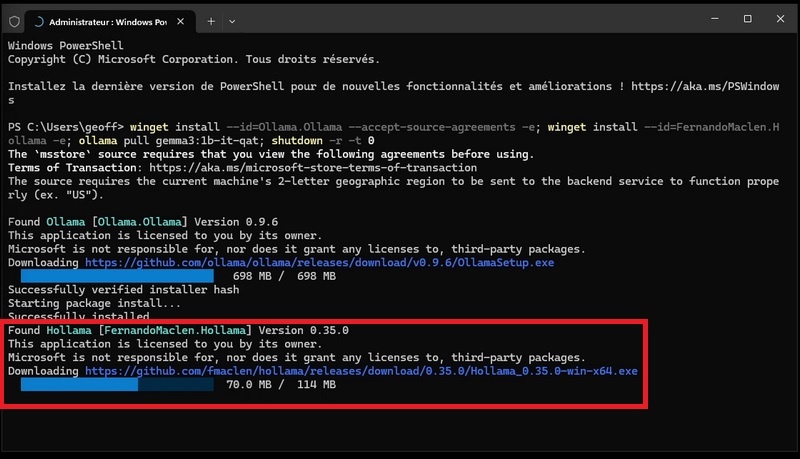
- L’instance locale Ollama étant installée, l’installation de l’interface graphique Hollama s’effectue de manière automatique.
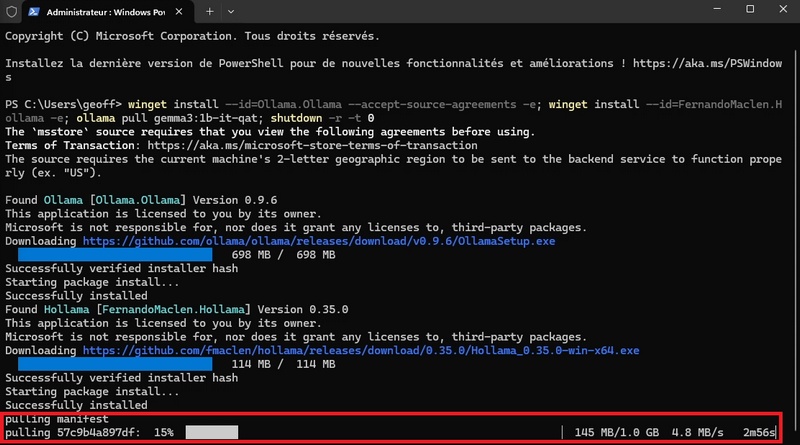
- Une fois ce processus d’installation terminé, le téléchargement du modèle gemma3:1b-it-qat sur l’instance locale Ollama se lance de manière automatique.
- Une fois le modèle téléchargé, le système redémarre automatiquement. Une fois redémarré, vous pouvez alors constater que l’icône de l’application Hollama est disponible sur le Bureau.
![]()
Finalisez l’installation
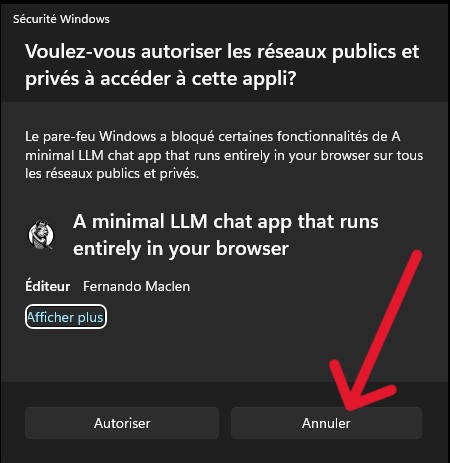
- Double-cliquez sur l’icône Hollama présent sur le bureau pour lancer l’interface graphique. Une notification du pare-feu Windows s’affiche, cliquez sur [Annuler] pour bloquer les flux entrants.
- Une fois l’application démarrée, celle-ci s’ouvre directement dans les paramètres de l’interface.
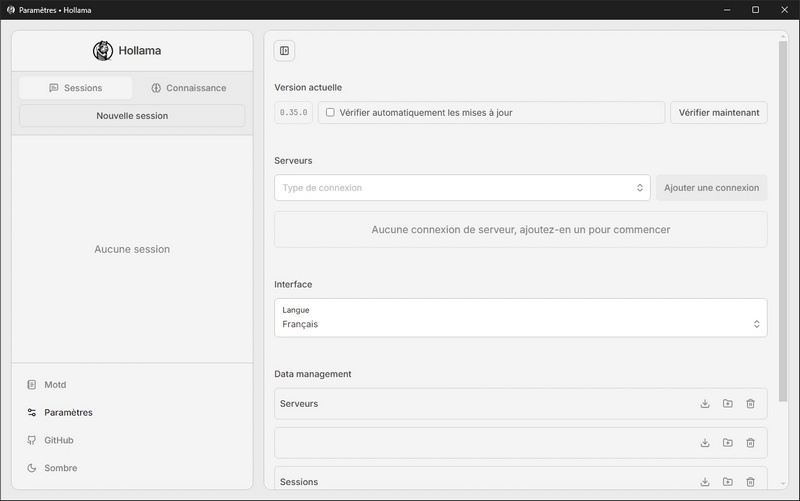
- Dans la section Serveurs, sélectionnez “Ollama” dans la liste déroulante “Type de connexion” puis cliquez sur [Ajouter une connexion].
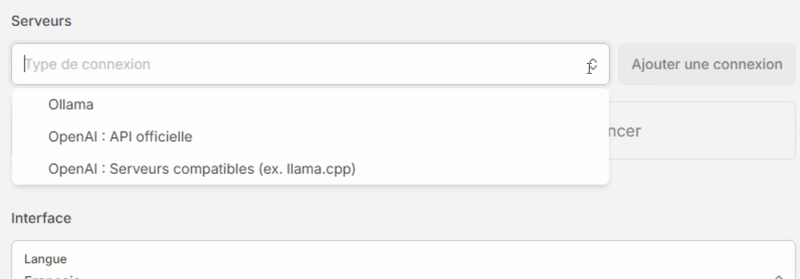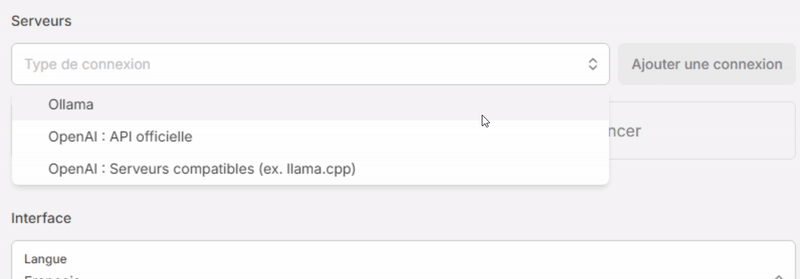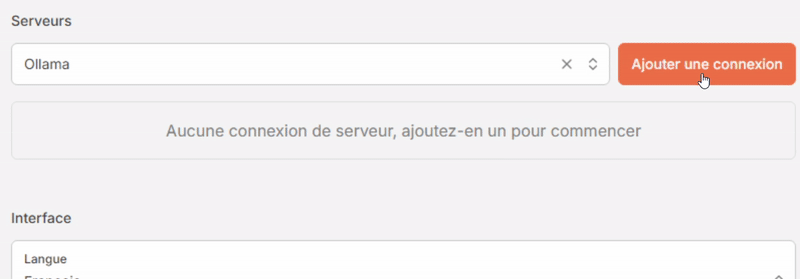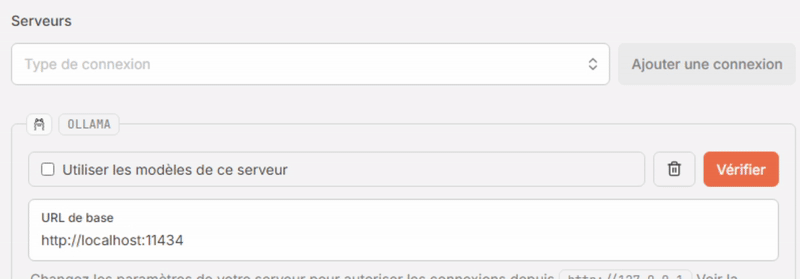
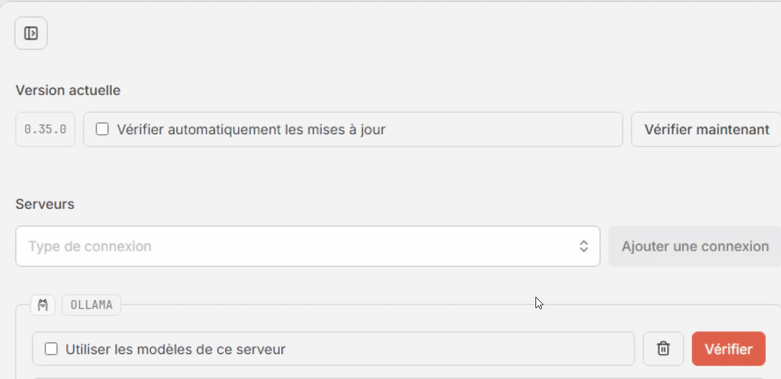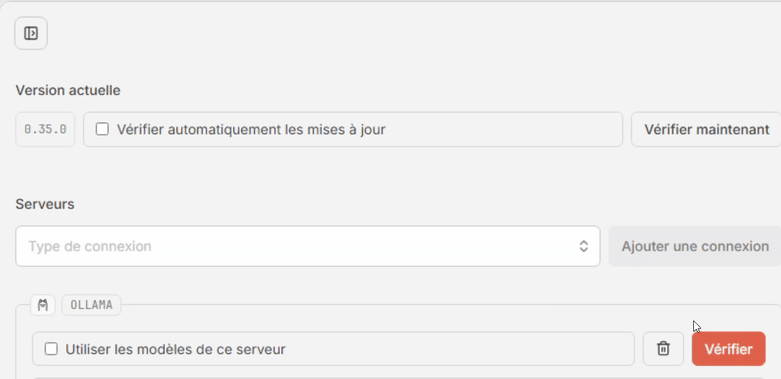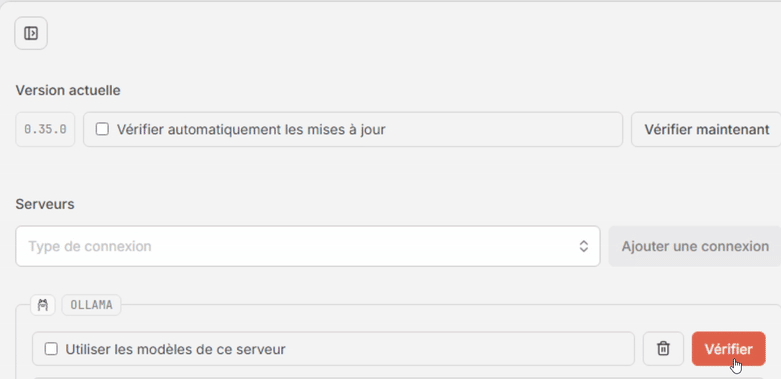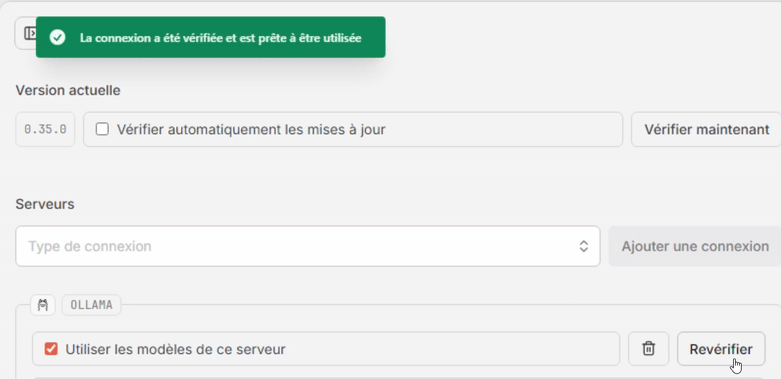
- Cliquez sur [Vérifier]. Si tout va bien le message “La connexion a été vérifiée et est prête à être utilisée.” s’affiche dans un encart vert en haut de la fenêtre, et la case “Utiiser les modèles de ce serveur” se coche automatiquement.
Testez un premier prompt
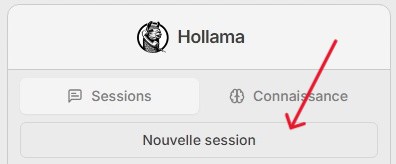
- Dans le menu de gauche, cliquez sur [Nouvelle session].
- Validez que le modèle est présent dans la liste déroulante, écrivez votre prompt, cliquez sur [Exécuter]. Patientez quelques secondes, et voilà, magie 😀
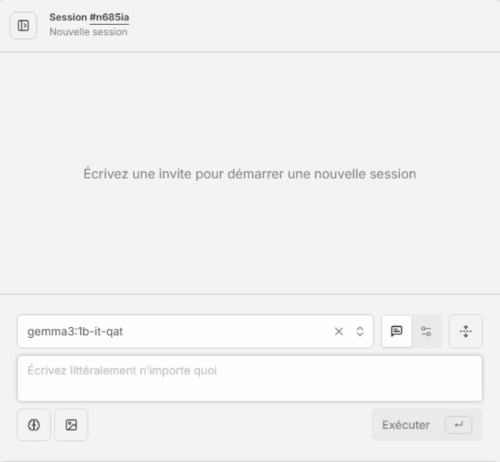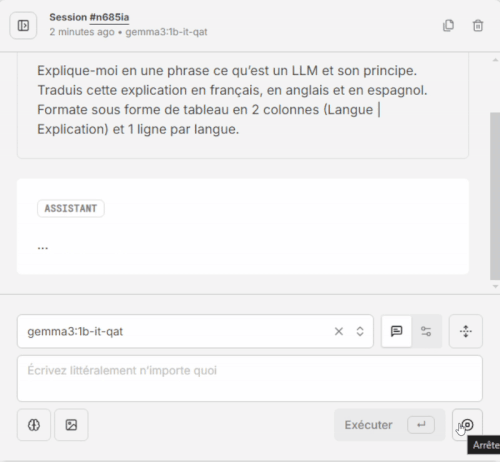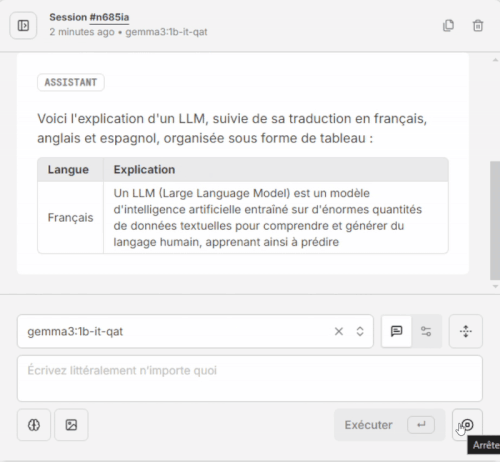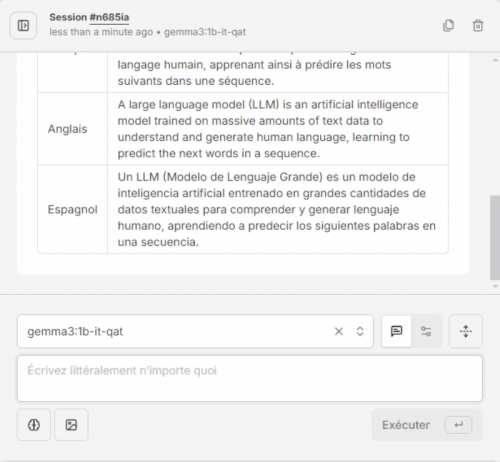
Comment télécharger d’autres modèles avec l’interface graphique ?
- Retournez dans les paramètres de l’application Hollama.
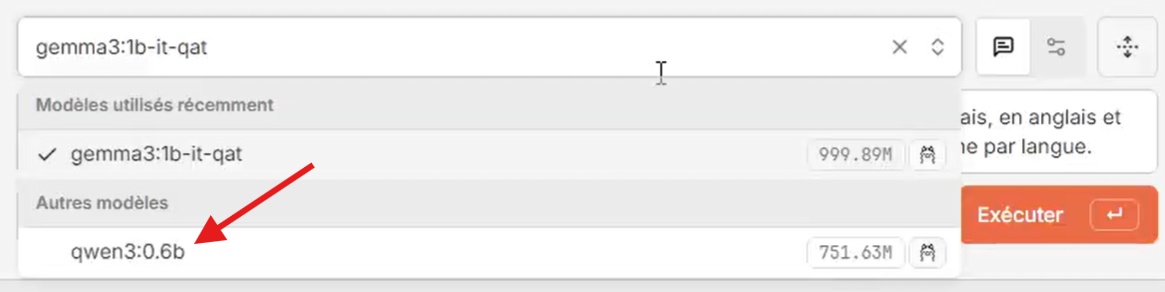
- Sous les paramètres de la connexion “Ollama”, cliquez sur le lien “Bibliothèque d’Ollama”. Dans la nouvelle fenêtre qui s’affiche, parcourez le catalogue de modèles disponible, copiez l’identifiant du modèle que vous souhaitez télécharger (exemple : qwen3:0.6b), puis fermez cette fenêtre.

- De retour dans les paramètres de la connexion “Ollama”, collez l’identifiant du modèle dans la boite de texte “Tirer le modèle”, puis cliquez sur le bouton rouge pour lancer le téléchargement.

- Un message d’information s’affiche en haut de la fenètre pour montrer la progression. Le nouveau modèle est téléchargé et prêt à être utilisé quand le message passera au vert.
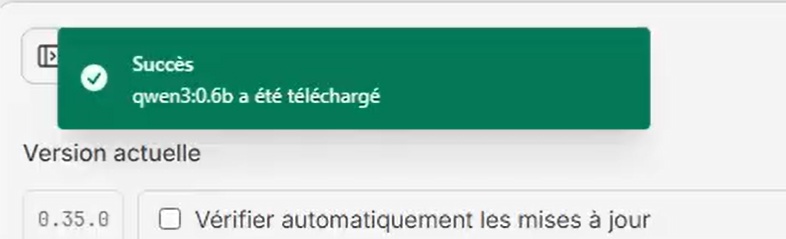
- Vous pouvez désormais choisir et utiliser ce nouveau modèle dans les sessions de conversation.
(Si besoin) Supprimer entièrement les composants installés
- Ouvrez PowerShell en mode administrateur (cf. 1ère étape),
- Exécutez la commande suivante pour supprimer tous les composants installés (applications et modèles) :
winget uninstall --id=Ollama.Ollama ; winget uninstall --id=FernandoMaclen.Hollama; winget source reset --force; rm $env:USERPROFILE\*ollama* -R; rm $env:USERPROFILE\AppData\Local\*ollama* -R; rm $env:USERPROFILE\AppData\Local\Temp -R; rm $env:USERPROFILE\AppData\Roaming\*ollama* -R; shutdown -r -t 0- Une fois les composants désinstallés, le poste va redémarrer automatiquement.
Conclusion
En quelques minutes, vous pouvez désormais expérimenter la puissance des LLM locaux sur votre PC Windows, sans abonnement ni dépendance au cloud. Que ce soit pour apprendre, obtenir de l’aide à la rédaction ou au codage, ou simplement explorer les dernières avancées de l’intelligence artificielle, Ollama et Hollama offrent une solution simple et accessible.
N’hésitez pas à tester différents modèles, à partager vos retours ou vos découvertes, et à contribuer à la communauté open source !